

尽管现在文生图模子(Text-to-Image Models)在生成高保真图像上说明罕见,但在叮属空间感知、空间逻辑推理及多看法空间交互等贴合现实场景的复杂空间智能任务时频频力不从心。现存评估基准主要依赖疏忽或信息疏淡的辅导词,难以遁入复杂的空间逻辑,导致模子在这些关节空间智能维度上的智商舛错被严重低估。
来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》建议了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 蓄意,以及围绕空间感知、空间推理和空间交互的 10 大空间智能智商维度蓄意,长远探伤文生图模子的空间智能智商鸿沟。
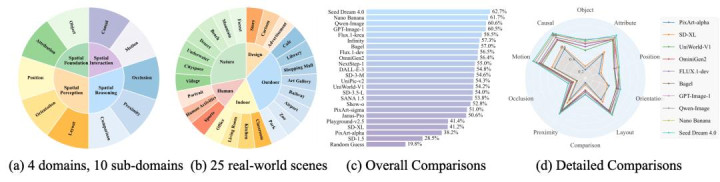
SpatialGenEval 将生图空间智能智商细分为 4 大维度,10 个子维度,遁入 25 个现实利用场景,基于 23 个 SOTA 模子的评估效果标明现时模子的空间智能智商仍有待大幅擢升

论文标题:Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models
论文赓续:https://arxiv.org/abs/2601.20354
论文代码:https://github.com/AMAP-ML/SpatialGenEval
中枢挑战:现在 T2I 模子空间领路 “浅表化” 与逻辑缺失
现存文生图模子诚然大概很好地完成 “生成什么”(What)的语义对皆,但在料理 “空间位置在何处”(Where)、“空间若何摆设”(How)以及物理天下中的 “空间交互逻辑”(Why)时,靠近着从 “基础感知” 到 “高阶推理” 的全场所挑战,包括:
1. 空间基础的 “属性漂移” 与缺失:模子诚然能画出物体,但在信息密集辅导词下,常出现物体漏画或属性绑定荒谬,无法保管 “万物各司其职” 的基础对皆智商。
2. 空间感知的 “几何偏见”:在料理物体精确位置、朝向及特定摆设布局时,模子时常倾向于生成 “默许姿态”(如正面视图),豪门国际官网娱乐网难以跨越 2D 画布收尾精确的空间定位。
3. 空间推理的 “逻辑盲区”:这是现时模子最大的短板。在波及相对数值相比(如 “红椅比蓝椅大两倍”)、3D 遮拦相关及物理距离附进性时,模子得分接近当场筹办,标明其穷乏对真什物理天下层级和深度的领路。
4. 空间交互的 “动态失真”:模子难以捕捉物体间的动态一忽儿(如超越中的足球)或物理因果逻辑(如撞击导致的落空),无法将躲藏的物理能源学鼎新为逻辑自洽的视觉图像。

上:现时生成模子在感知、推理和交互上的荒谬样例;下:现时评估基准存在信息疏淡 / 粗粒度 yes-or-no 评估
SpatialGenEval:波及空间基础、感知、推理和交互的空间智能 “全科扫描”
为了系统化地界说和评估文生图模子 “空间智能” 智商,盘问团队构建了一个头绪化框架,将空间智能解构为 4 大范围及 10 个关节子维度:
1. 空间基础 (S1/S2):多看法物体类别(S1)、多看法属性绑定(S2)。
2. 空间感知 (S3/S4/S5):空间位置(S3)、空间朝向(S4)与空间布局(S5)。
3. 空间推理 (S6/S7/S8):空间大小 / 长度 / 高矮等相比(S6)、空间附进性(S7)与空间位置遮拦(S8)。
{jz:field.toptypename/}4. 空间交互 (S9/S10):空间洞开交互(S9)与空间因果交互(S10)。
该基准测试遁入当然、室内、户外、东说念主类活动及艺术蓄意等 25 个现实天下场景,为其全心构建了 1,230 条 长文本、信息密集型辅导词。每个辅导词均深度交融了上述从基础属性、布局到高阶遮拦、因果推理等 10 个空间子范围及对应全维度问答。值得顾惜的是,OD体育app官网每个辅导词长度约 60 词,允许同期兼顾依赖 CLIP 编码模子(77 tokens 为止)和保抓高度信息密集。

SpatialGenEval 评估数据构建过程

SpatialGenEval 通盘 10 个空间维度的辅导词过火问题展示

中枢发现:空间推理也曾主要瓶颈
盘问团队对 23 款前沿的开源与闭源 T2I 模子进行了小心评估,揭示了以下行业近况:
空间推理是中枢薄弱法式:在波及相比和遮拦的空间推理子任务中,多数模子的得分仅在 30% 傍边,接近当场筹办水平(20%),这标明现在的模子广阔穷乏对 3D 场景结构和逻辑相关的蚁合。
开源模子正快速追逐:评测露馅,最强的开源模子 Qwen-Image (60.6%) 说明已与顶级闭源模子 Seed Dream 4.0 (62.7%) 基本抓平,但均仅达到合格线水平,空间智能仍有纷乱擢升起间。
苍劲的文本编码器至关进军:使用高性能 LLM(如 T5 或大型话语模子)行为文本编码器的模子(如 FLUX.1),在理会复杂空间指示时权贵优于仅依赖 CLIP 的模子。
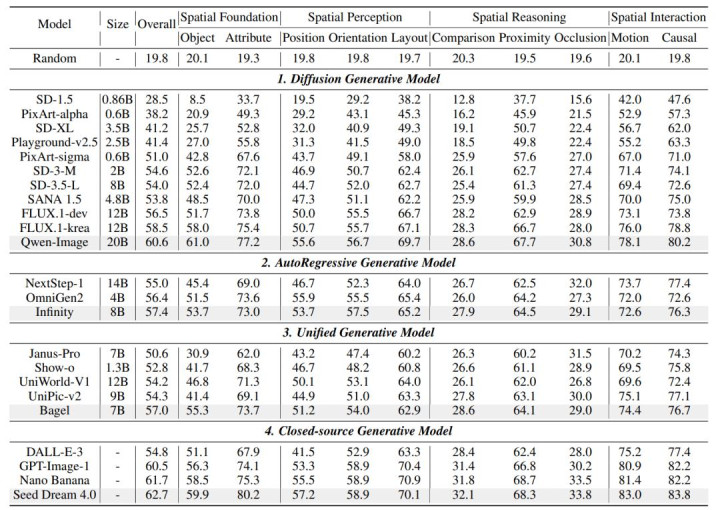
基于 Qwen2.5-VL-72B-Instruct 的自动化评估效果
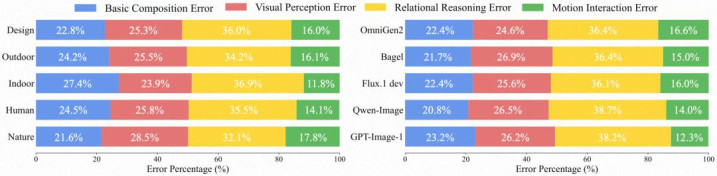
左:通盘评估模子的荒谬类型隔离;右:高优模子的荒谬类型隔离
数据中心范式:擢升模子空间智能的灵验旅途
除了评估,该盘问还建议了一种基于已有生成图像的改革决议。团队通过多模态大模子(MLLM)重写辅导词以确保图文一致性,构建了包含 15,400 对图文数据的 SpatialT2I 数据集。对主流三大类模子(Diffusion-based, AR-based,Unified-based 模子)进行监督微调效果在空间评估目的有权贵增益,生成的图像在物理逻辑和空间布局上更具真实感。

微调模子后的生奏效果对比
回归与揣度
SpatialGenEval 为 T2I 模子从 “好意思学生成” 迈向 “逻辑感知” 开导了一条新的评估阶梯,惟有让模子确实蚁合 “万物各得其所 (Everything in its place)”,生成式 AI 能力在机器东说念主赞助、室内蓄意、自动驾驶仿真等对空间维度有严苛条款的范围中开释确实的分娩力。
作家团队先容
阿里高德的机器学习研发部,相接公司重心业务,包括土产货生涯场景中的告白创意、商品蚁合、试验智能创作和分发,出行场景的 AI 智能化等,部门盘问范围粗俗,包括但不限于以下标的:(1) 多模态大模子;(2) 图像生成 / 剪辑好意思化;(3) 视频生成 / 蚁合;(4) Agent; (5) 时空数据挖掘;(6) 智能推选;(7) 高性能推理等。团队技能氛围好,成漫空间大,领有填塞的研发资源和无数的业务利用数据,多篇论文入选 paper digest 最有影响力论文名单。